
量化值:100%
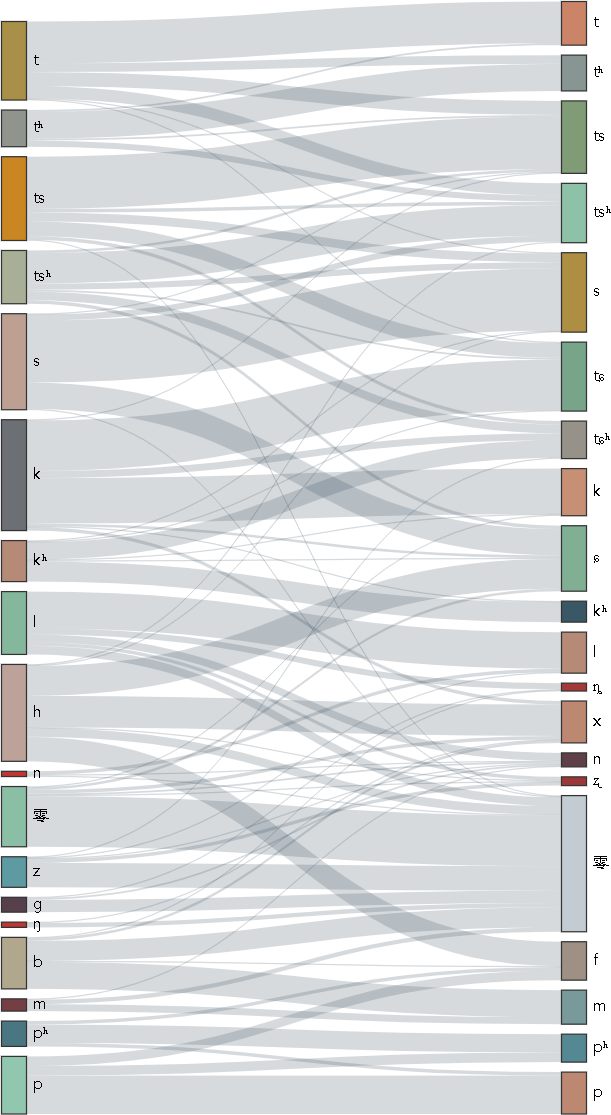
量化值:60%
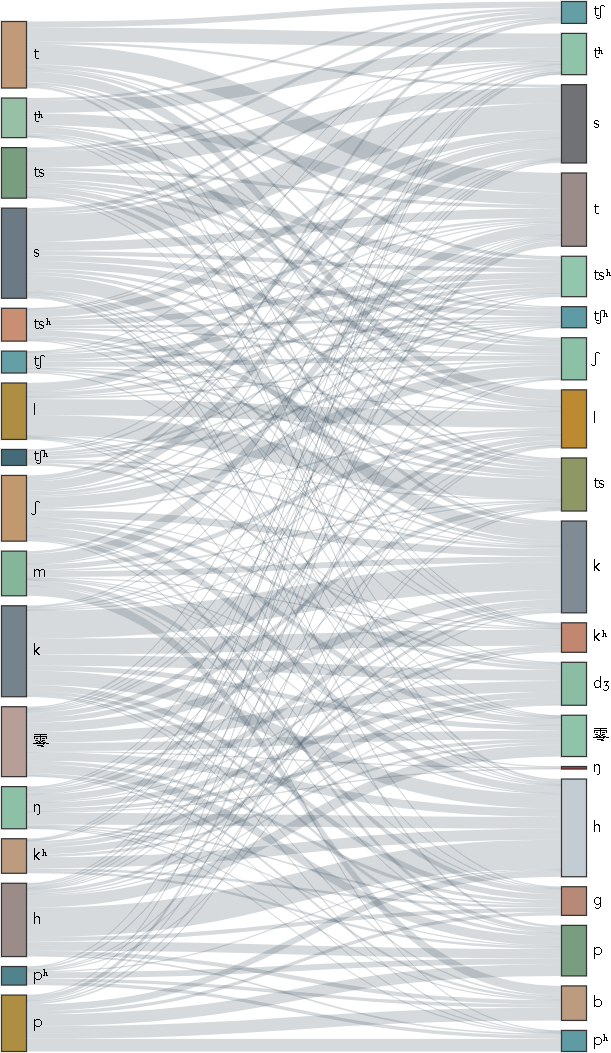
量化值:20%
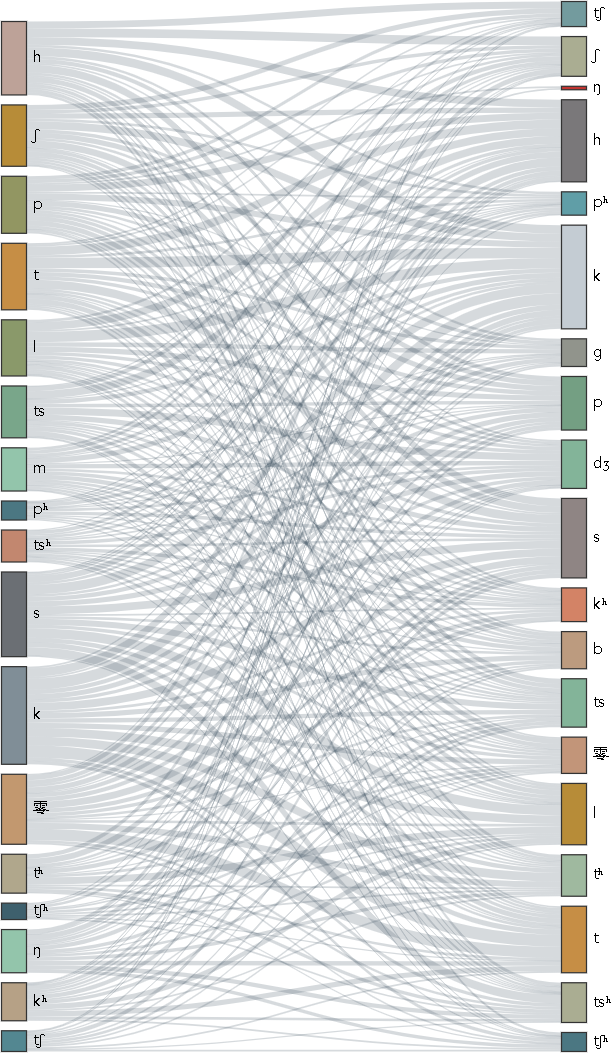
量化值:接近0%
圖:「語音映射有序性」舉例(以聲母為例、把相同義項上的聲母連成線)
古音小鏡漢藏語系關係樹用「語音映射有序性」來判斷語言之間的親疏關係,它原理容易理解:把2個語言中相同義項上的音(比如聲母)連成線,形成一張映射表,那麼易知,連線有序則語言親,連線混亂則語言遠(如上圖)。
我們這行的創始人是深圳程序員黃藝華,他最先發明這個方法,他用「熵」量化有序性,為漢語方言分區,取得了很好的效果(見此)。 我在「漢語地理」欄目也使用這類方法為漢語建樹(見此)。 當時,我所用的語保工程漢語字表整齊劃一,對量化方法要求低,現在面對材料複雜的漢藏語系,有了新挑戰:
① 不同詞數要公平對比。同一個語言,1000詞表進去,200詞進去,出的結果要大致相同。
② 不同音系結構要公平對比。兩個近親方言,一個100韻母,一個30韻母,出結果要大致相同。
為實現這2個目的,漢藏語系設計新的量化方法。考慮到大部分朋友看到公式就頭疼,下面略去公式,用數字舉例,直觀講解。
注意下面會有兩個重要數值:
①
②
二、絕對信噪比(受詞數、音系結構影響)
換個視角,有序性等效於信噪比,即每根對應線的寬度較隨機概率的富餘(信)是否顯著於後者的不確定程度(噪),這話有點繞,下面舉例。
比如,A語言的[h]聲母和B語言的[ŋ]聲母,在詞表中的相同義項上碰面20次,如果這兩個語言毫無關係,算出隨機碰面12次,這12次中不確定程度2次,那麼信噪比是:(20-12):2=4,統計理論中又叫Z分數。該數值越大,[h]-[ŋ]有關係的概率就越大。
不確定程度高斯分佈,可用概率論知識算出來(攤開講要一屏幕,請複習大二課程《概率論和數理統計》中相關內容)。
以上是[h]-[ŋ]的值,依次算出所有聲母的值,再以詞數權重得到均值,把它稱為聲母的「絕對信噪比」。同理算出元音、韻尾,再取三者均值,即總「絕對信噪比」,這個數值可判斷兩語言是否有關係。
三、相對信噪比(克服詞數、音系結構影響)
「絕對信噪比」實現了「判斷兩個語言是否有關係」,但在「兩對(4個)語言誰更親」這個問題上,它有缺點。你肯定已經想到,「絕對信噪比」對詞數、音系結構敏感,詞數越少它越小,音位越少它越大,它沒有實現那2個目標,因此我們需再推進一步:相對信噪比。
②再把映射表設置到最有序狀態(就像兩個剛分離的最近親語言),讓它最有序,算得它的「絕對信噪比」B(數值以5-30最常見)。
那麼易知,實際「絕對信噪比」會落在A和B之間,這個相對位置,即(B-A)/B,把它稱為「相對信噪比」(數值在0-100%之間)。這個數值中,詞數差異、音系結構差異被抵消,實現了那2個目標。
這樣,問題解決了!
四、對比詞約束至300個義項
還有一個小問題沒解決:用核心詞比,和用生僻詞比,所得結果,肯定不同,前者更高。
為了義項的基本公平,我制定了一份300穩定義項表,選用漢藏語系同源性好、傳承穩定的義項,要求對比詞都必須在這300義項中,除此之外的刪除,不做任何比較。
這樣,大部分材料之間,可比義項在200-300個之間,少於120個用綠色字警告(表示結論稍差、謹慎參考),少於60個用紅色字警告(表示結論很差、請捨棄)。
300義項詳情 >>
