哈尼組被分為三個層級:
① 高層級:哈尼組。
② 中間層級:核心哈尼-碧卡哈尼-基諾-畢蘇。
③ 低層級:以ABCD…標號,相同的字母表示同一個最小單位。
這些區塊由聚類程序依據數值的相似程度自動判斷完成,完成後人工檢查,排查錯誤和調整,優化層級和次序。
聚類時,各區塊之間取集體均值,具體為:
① 高層級之間(比如哈尼組-拉祜組比較),以該層級所有語言整體取均值,參與聚類(見圖2)。
② 中間層級之間(比如基諾-畢蘇比較),以該層級所有語言整體取均值,參與聚類(見圖2)。
③ 低層級之間(比如碧約-卡多比較),以該層級所有語言整體取均值,參與聚類(見圖2)。
④ 低層級內部(每筆材料之間),以正常方式聚類。
均值取法:從大到小排序,刪除頭部1/4數據,刪除尾部1/4數據,以中間1/2數據取均值,類似中位數但比中位數更合理。
(注意這和常用的平均連接法不是一回事,後者只對單筆材料做平均)
為什麼要這樣做:
① 克服異常數值帶來的樹形破壞,異常數據會被均值熨平。
② 加減新材料對結果影響小,不會出現新增常規材料後樹形大變的情況。
③ 語言材料越多結論越可靠,支持大量材料建樹。
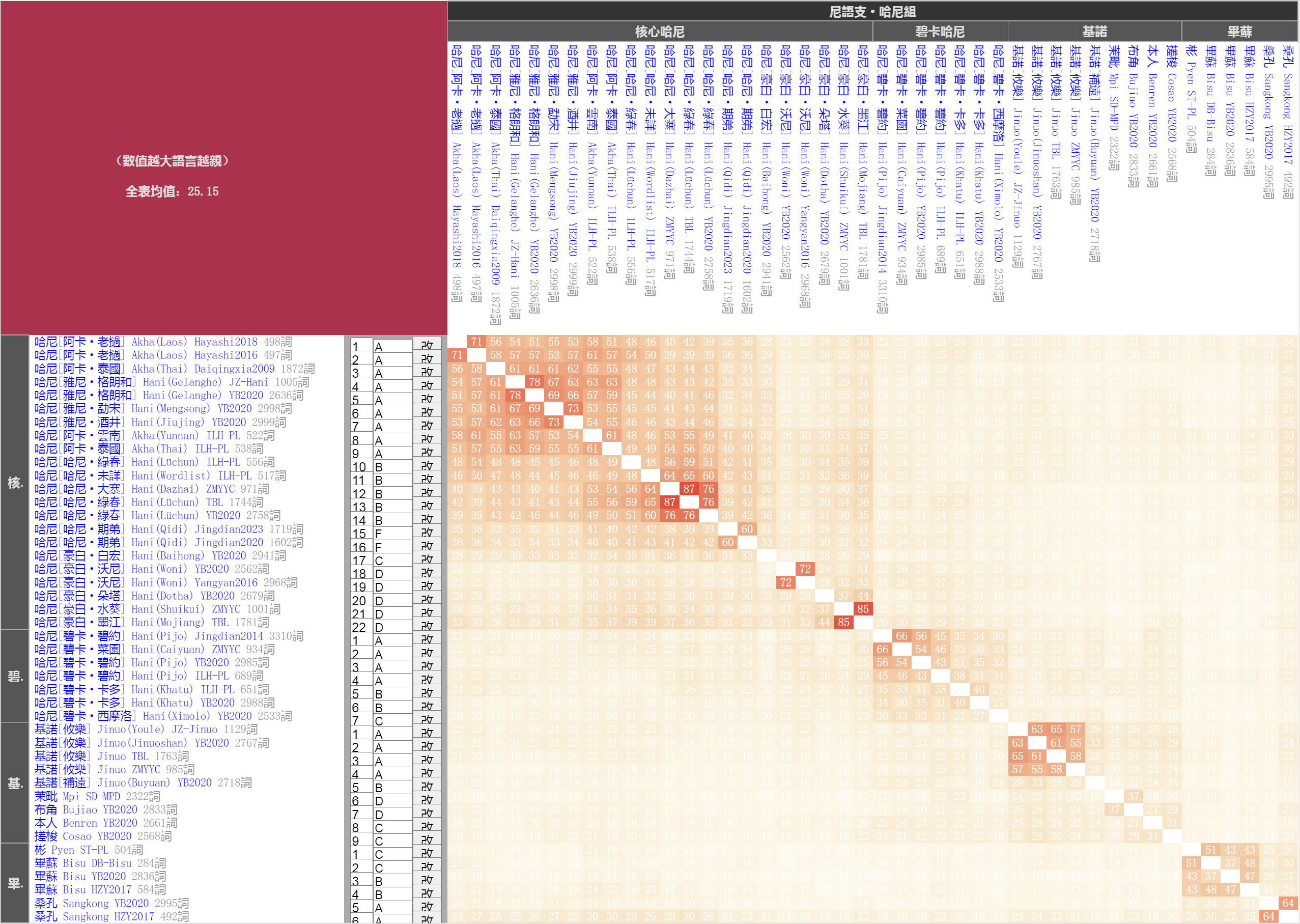 圖1:哈尼語組原始熱圖(用於觀察和分析)
圖1:哈尼語組原始熱圖(用於觀察和分析)
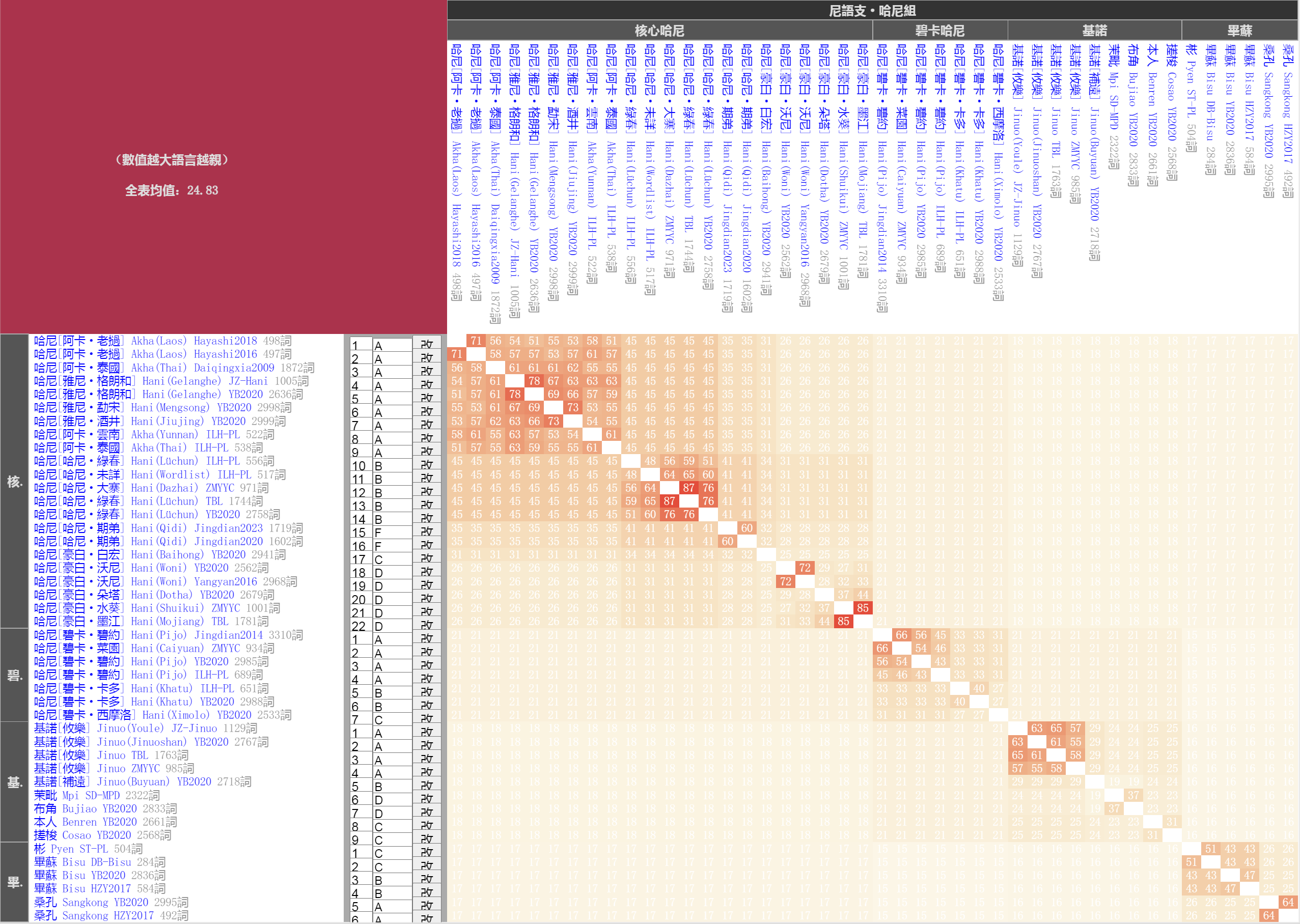 圖2:哈尼語組區塊均值熱圖(用於聚類、注意均值有層級性)
圖2:哈尼語組區塊均值熱圖(用於聚類、注意均值有層級性)
(提示:上圖數據僅示範之用、網站已更新數據、這是老舊的測試數據)
